摘 要:精确串匹配是计算机领域的一个经典问题。在大数据时代,海量的数据给串匹配问题带来巨大的挑战。当前,GPU的应用得到学术界和工业界的广泛关注,基于GPU的串匹配算法研究已成为学术界的焦点。为展示近年的研究,综述了基于GPU的精确串匹配技术,针对不同的算法和GPU架构介绍精确串匹配技术在GPU上的改进:不同算法的改进具有差异性,研究时需扩展具体算法,并比较上述算法的优缺点。最后对评测指标进行介绍,展望其发展趋势。
关键词:模式串匹配;精确串匹配;GPU加速;计算统一装置结构
引言
精确串匹配问题是计算机领域的一个经典问题,它广泛应用于信息安全、文本检索和计算生物学等领域。著名的入侵检测系统Snort[1,2]包含多种规则匹配法,如BoyerMoore(BM)、WuManber(WM)和AhoCorasick(AC)算法。其中BM算法适合单模式串匹配,AC和WM算法适用于多模式串匹配。随着计算机网络的快速发展,需要处理的数据规模越来越大,因此在上述领域中对匹配效率的要求也越来越高。单纯基于软件的串匹配算法虽然实现上比较灵活,但其性能已经难以满足当前日益增长的网络需求。如何对大规模模式串进行实时匹配是目前工业界和学术界面临的严峻挑战。与此同时,随着并行计算机体系结构的蓬勃发展,学术界逐渐将串匹配问题的视点转向众核处理器或一些专用硬件设备,如GPU、FPGA、TCAM(ternarycontentaddressablememory)等。因此,研究并设计基于硬件的模式串匹配算法具有重要的理论价值和实际意义。在硬件实现方面,PFGA和TCAM具有一定局限性。文献[3]详细地对FPGA和TCAM两种硬件设备的优劣性进行了介绍。基于FPGA的串匹配方法存储空间有限,不能存储大规模的模式串;基于TCAM的串匹配方法对于长模式串的处理比较复杂,降低了匹配速度,同时硬件成本较高,耗能较大。基于GPU的串匹配方法通常采用GPU与CPU相结合的异构计算架构,GPU负责高度并行计算密度的任务,CPU负责串行计算密度高、控制逻辑复杂的任务。因此不仅提高了计算能力,而且降低了成本、节约了资源,是当前高性能计算应用比较广泛的方法。GPU具有并行计算的能力,它广泛应用于机械力学、数学计算、物理学、图像处理和字符串匹配等方面。
本文对基于GPU的精确串匹配技术的研究进展进行了综述。根据不同的算法特征以及GPU独特的架构特点对精确串匹配技术在GPU上的改进进行介绍;对基于GPU的精确串匹配算法的优缺点进行了总结。最后,介绍和分析研究中的性能指标,并对基于GPU的串匹配技术的未来发展趋势进行了展望。
GPU简介
近年来,由Intel、IBM、SUN、AMD等厂商生产的CPU虽然有很大的发展,但是CPU的性能提高速度却远远不能与20世纪80年代、90年代初相比。PU显示出在单线程处理性能方面的限制,这些限制来自于功耗墙(powerwall)、存储墙(memorywall)、频率墙(frequencywall)和过低的指令级并行。GPU的出现为算法设计和优化带来了新的契机。
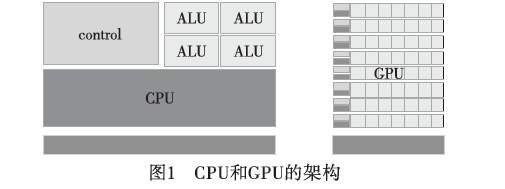
在架构上GPU和CPU的差异十分明显。如图1[4]所示,CPU采用复杂的控制逻辑,能适应复杂运算环境,大部分的晶体管用于构建控制电路和cache,少部分晶体管完成实际运算工作;GPU控制相对简单,对cache的需求比较小,流处理器和显存控制器占据了绝大部分晶体管,主要负责大规模的密集型数据并行计算。GPU的执行能力往往是CPU的10~100倍[4]。
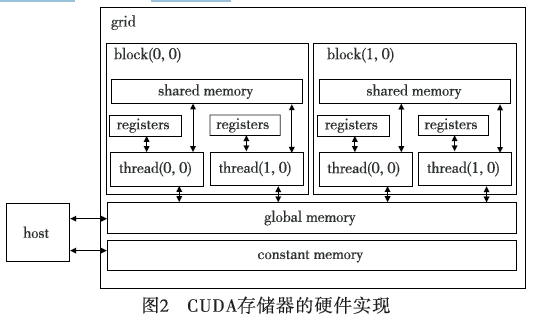
2007年,NVIDIA[5]发布了CUDA(computeunifieddevice architecture)并行计算架构。CUDA并行计算架构采用一种新的通用并行编程接口,在C语言基础上添加了适用于GPU并行计算的API和开发库,能在GPU强大计算能力基础上建立起效率更高的密集数据计算。CUDA中最基本的处理单元是流处理器SP(stream processor)。最小的程序执行单位是thread(线程),多个thread组成一个block(块),多个block组成一个grid(网格),如图2[4]所示。同一个block中的thread可访问同一块共享存储器(sharedmemory)。此外,GPU的存
储器还有本地存储器(localmemory),全局存储器(globalmemory)、纹理存储器(texturememory)、常量存储器(constantsmemory)、寄存器(register)等。
2基于GPU 的模式串匹配算法分类
近年来,关于在GPU上实现串匹配算法的研究越来越多。文献[6]将BF、KMP、BM和QuickSearch几种在线的经典字符串匹配方法在GPU设备中进行了实现。它采用了DNA序列,文本数据直接存储在全局存储器中或共享存储器中,文中对不同算法的加速比进行了比较,得出无论实现在串行结构还是GPU上的并行结构,运行时间都会随着文本大小、线程数目的不同而随之变化,当文本比较大、规则串比较小时,并行结果的加速比是串行的24倍以上。在文献[7]中,为了检测癌症的
基因序列,简要对比了BF、BM、KMP、MSMPMA、IKPMPM 、EPMSPP算法和并行算法(parallelalgorithm)的优劣,并行算法
以能并行计算、预处理时间最小的优势成为文中采用的算法,它将输入文本分为不同大小的chunk,每个线程处理一个基因模式串,所以对一个chunk可以并行匹配。文中指出随着基因模式串规模的增长,GPU相比CPU在匹配方面的时间几乎不增长,并行效果的加速比是串行设备的30倍。传统的精确串匹配算法种类繁多,分类方法也不尽相同,根据文献[8]可分为单模式串匹配算法和多模式串匹配算法,单模式串匹配算法一次可以匹配一条规则,多模式串匹配算法一次可以匹配多条规则。单模式串匹配算法主要分为BF、KMP、BM和Sunday等算法;多模式串匹配算法可以分为AC、WuManber和hash等一系列算法。在GPU方面,上述算法近年来的发展历程如表1所示。
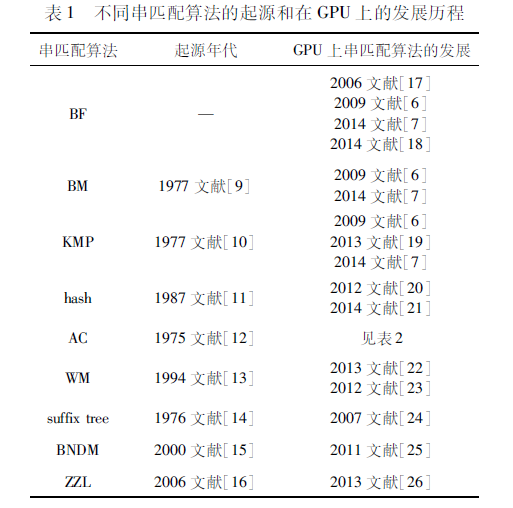
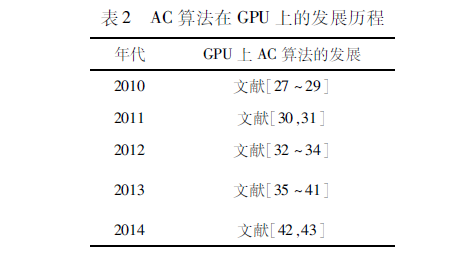
从表1中可以看出,基于GPU的精确串匹配算法在最近六年中发展迅速,多种经典算法都在GPU中得以实现。表2描述了AC算法在GPU上的发展历程,该算法在近几年内发展飞速。本文将从单模式串匹配算法和多模式串匹配算法分别介绍各算法的具体发展和改进。在GPU架构中改进方面介绍了利用共享内存和循环展开(loopunrolling)来进一步优化时间效率。
3基于GPU的单模式串匹配算法
基于GPU的单模式匹配算法主要包括BF、BM、KMP、Hash等算法,以下根据近几年的文献进行了总结,从各算法的改进方向给予介绍'"
3.1基于GPU 的brute force,算法改进
Bruteforce(蛮力,BF)算法是最简单的字符串匹配算法,其思想是从规则中的第一个字符开始向后匹配,直到遇到不匹配时,从文本串的下一个字符开始再进行匹配。它的优点是无须进行预处理,不需要多余的空间进行操作,时间复杂度是O(mn)。理论上算法性能远差于KMP、BM、BOM等,但在具体应用中,最坏情况极少出现,性能还是较优的。BF算法在CPU中的实现机制较为简单。文献[17]利用GPU实现BF串匹配算法,优化改进是将其中的while等循环控制语句转换为数值计算语句,实验对比了GPU和CPU上匹配时间。实验结果表明基于GPU的并行算法能够取得较好的加速比,同时也给出了在现有GPU架构上通用计算的瓶颈问题:在使用GPU进行通用计算时,应当尽量减少在一个计算周期里读取纹理存储器(texturememory)的次数。文献[18]为了高效率地对DNA序列探测,采用了BF算法在GPU上实现串匹配,指出基于GPU的BF并行方法的性能要优于传统的串行算法。虽然蛮力算法思想比较简单,实践到GPU上可以对文本任意位置开始进行匹配,而不必考虑“文本漏检”的问题,但是由于算法原始,在极端情况下性能低下。
基于GPU 的多模式串匹配算法
基于GPU的多模式串匹配算法包括AC、suffixtree、BNDM、ZZL等一系列算法,各算法的改进各不一样。其中对于AC和WM算法的改进种类繁多,下面将主要介绍AC和WM算法的改进,同时简要介绍其他算法的改进。
4.1基于GPU的AC算法改进
AC算法(AhoCorasickalgorithm)是多模式串匹配算法中比较成熟的一种,它对于文本串不进行回退操作,且能同时进行多模式串的匹配,建立一个trie树,从而实现对于多条文本串规则的匹配。现已成为常用的模式串查找算法,如著名的入侵检测系统Snort的核心就是基于AC算法。近期研究比较经典的是PFAC和GAC算法,下面简要介绍各自的改进。
411 基于GPU的PFAC算法
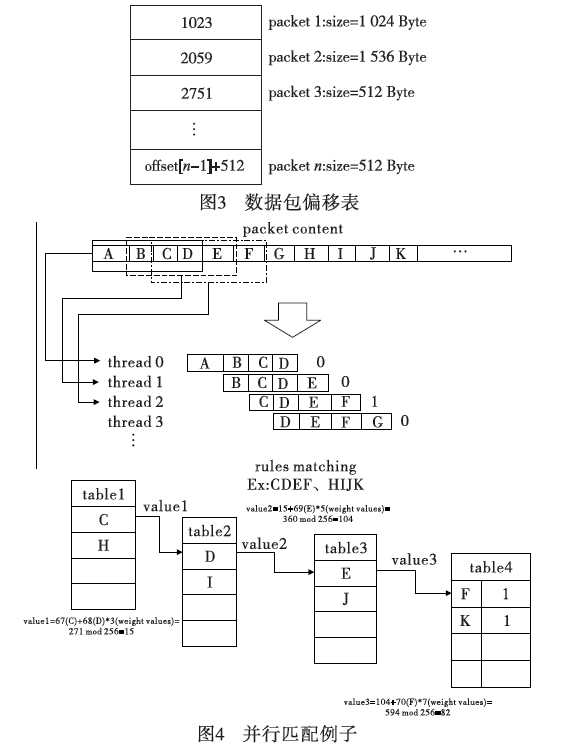
文献[28]中提出了PFAC(parallelfailurelessAC)算法,主要思想是一个线程匹配文本串中每个比特,将其作为文本串的初始状态进行AC自动机的匹配,如图5所示。并且AC自动机去除了失效边,减少了转移边的数目。它具有以下几个优点:a)不存在对文本的依赖,可以从任意位置开始匹配,加大了吞吐量;b)最坏和平均线程的生命周期很短,由于很多线程从开始进行匹配的时候是无效的转移状态,它们结束的时间很早;c)删除了失效边使得内存占用比较小。
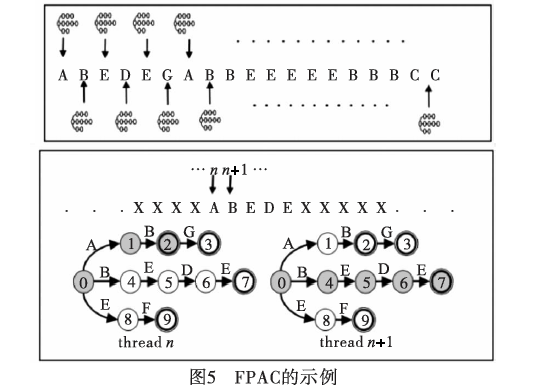
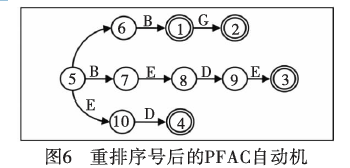
文中线程分配原则采用平均分配的方法,即若共有n个线程、m比特的数据流(m能整除n),那么每个线程分到m/n个比特,以第一个线程为例,它将定位在第0个位置,第n个位置,第2n个位置,第3n个位置,…,第m-n个位置。结构上将AC自动机放在共享存储器中,并尽可能多地运用GPU的线程。文献[39]中为了减少对output表的查询,对状态编号进行了重排,如图6所示。对于可接收状态(设总共有n个),编号设置为1~n,初始态设置为n+1,当查询到了状态编号小于n+1时,就到了可接收状态,即可匹配。与此同时,每次从全局存储器中同时取出n个线程所需要的文本量来节省全局存储器访问带来的延迟。当数据规模达到256MB时PFAC算法实验结果的吞吐量能达到143.16Gbps。然而,PFAC算法也有其缺陷性,它应用的模式串长度较小,不适用于大数据规模的模式串;AC自动机状态数量多,没有作相应的压缩处理。
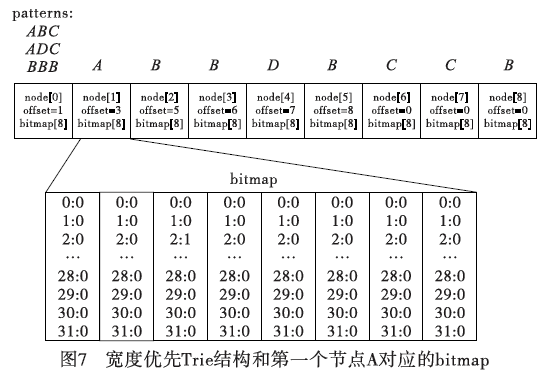
面对AC自动机状态数量多的缺陷,文献[42]对PFAC的存储进行了改进,对AC自动机作定长压缩。具体的存储方式是将AC自动机存储采用特殊的方式,如图7所示,将原来的AC自动机按照宽度优先的原则进行顺序存储,每个状态包含三个结构:节点标号node[]、偏移量offset和状态偏移值bitmap[8][32],256种转移状态用bitmap来存储。由offset确定当前状态转移的第一个节点标号,其他转移节点标号由offset和bitmap共同确定。下面举例说明:图7中规则给出了三条,对应的AC自动机中第一个节点为A,子节点是B和D。A转移状态先通过offset到达B,则为node[3],为了找第二个节点,增加了populationcount操作,寻找当前在D(以ASCII码为准)之前的bitmap中有i个1,进行相加,即
curNode=curNode→offset+i
上述改进的优点是比PFAC算法有效地降低了空间。当字符集是32时,该算法能降低187%的空间,并能达到8Gbps的吞吐量。缺点在于该算法在字母集(Σ)比较小的应用场景下表现得比较好,如果字符集太大,效果不明显。
412 基于GPU的gAC算法
由于GPU的SPMD机制中分支转移处理对性能的影响很大,所以文献[29,34]对AC自动机的failure函数进行改进,即在匹配时不使用failure函数来指示当失效时需转向的状态,而直接使用goto函数来完成failure函数的功能,如图8和9所示。在
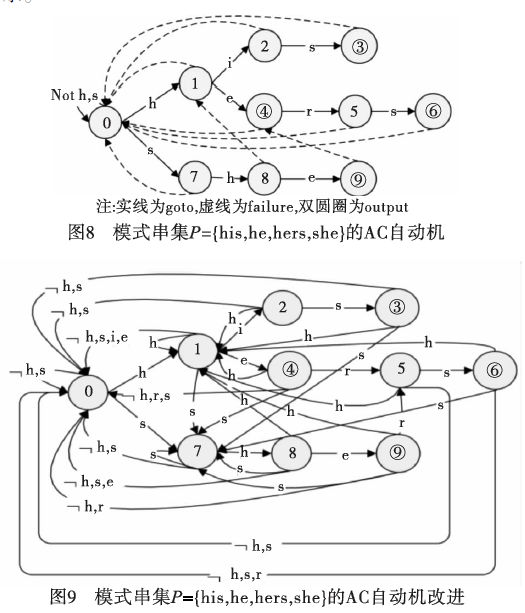
在文本数据结构上采取与3.2节一致的方法,将文本平均分配给每个线程,所不同的是每个线程分配的大小变为textSize PAGESIZE+maxPatternLength其中:textSize为单个文本大小;PAGESIZE为页面大小,一般为2KB,对于不足PAGESIZE大小的文件或分割后的最后一页将
填充至PAGESIZE;模式串的最大长度为maxPatternLength,如图10所示。每个页面的前8Byte为页面头,记录该页所在文本文件的ID号和偏移量offset。由于自动机状态占用空间比较大,所以模式串构成的自动机存储在纹理存储器中;匹配结果占用空间比较小,需要全局操作,故存储在全局存储器中;待匹配文本现分为一个个页面大小,将页面部分内容从全局存储器批量搬移到共享存储器中,匹配程序从共享存储器中读取。
gAC算法的优点在于它使得AC自动机的结构发生了变化,分支转移操作减少,从而使得访问延迟大大减少。当模式串数目为2400个、数据规模为800MB时,gAC算法的实验结果的并行匹配速度能达到51Gbps,是单机串行方法的28倍。gAC算法的缺点在于文本需要重叠,降低了吞吐量。
5GPU基于WuManber的8*139(,) 算法改进
WuManber算法是一种常用的多模式串匹配算法,它是BoyerMoore[9]算法的一种派生形式,采用了BoyerMoore算法的框架,使用长度为b的字符块B(blockcharacter)而不是单个字符来计算坏字符(badcharacter)的距离表SHIFT。此外,在进行匹配的时候,它用散列表hash选择模式串集合中的一个子集与当前文本进行匹配验证,能减少运算。WuManber算法的执行时间主要依赖模式串集合中最短的模式串长度,它不
会随着模式串集合大小的增加而成比例增长,其时间要远少于使用每一个模式串和BoyerMoore算法对文本进行匹配的时间总和。文献[22]介绍了GWM的算法,它在GPU上实现了WM算法。当模式串长度为32、数目为3000条时,所得性能是传统串行算法的12倍左右;当模式串长度不相等、数目为5000条时,所得性能是传统串行算法的11.2倍。
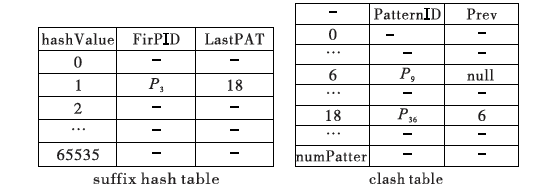
文献首先将传统hash链表设置为二维的,为防止哈希冲突添加了clash表,如图11所示。其中B值为2,所以共有65536(256×256)个块字符,hash表设置为hash[65536][2]。FirPID是hash表中哈希值为h的第一条规则ID,LastPAT是哈希值仍为h的最后一条规则ID。图3中展示了hash过程,举例如下:哈希值为1的规则共有三条,分别是P3、P9、P36。故FirPID=P3,LastPAT=18,18是在Clash表中表示P36的位置。Clash表中的Prev代表与当前规则hash值相同的前一条规则ID。Prev=null表示hash值相同的本条规则的前一条规则在hash表中的FirPID位置。
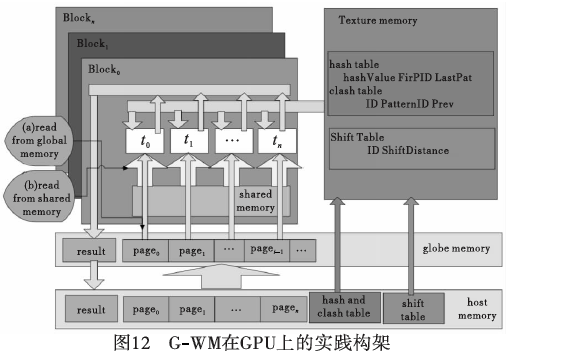
其次,在结构上将hash表和Clash表存储在纹理存储器中。文本采用3.2节的文本分割方法,将文本分割成一个个均等page。对于page的存储采用了两个版本,版本1是将page存储在全局存储器中,每个线程直接读取全局存储器中的内容;版本2是将文本page从全局存储器移到共享存储器中,每个线程都从共享存储器中读取数据。整体架构如图12所示。
在GeForce9600GSO和GTX570(计算能力分别为1.1和2.0)两种实验平台上对吞吐量进行比较,得出GTX570比GeForce9600GSO的吞吐量更高。对于文本的不同存储,发现存储在全局存储器中的文本速度更快些。虽然片上共享存储器的访问速度比片下的全局存储器要快20倍以上,但是数据从全局存储器移到共享存储器的通信代价比较大,从而吞吐量下降。
文献[23]在Geforce9800GT上面也实现了WM算法GPU的加速。文本数据处理与3.2节一致,文献在GPU的优化方面为了节约内存带宽采取了从常量存储器读取数据,这样在某些情况下可以有效提高性能。与此同时,纹理存储器中的内容在芯片有缓存,并且是只读的,故能减少显存的请求有效提高带宽。实验中比较了不同大小的grid和block分布对于加速比的影响,模式串数目在100~2000、长度在6~17时,最低加速比仍能达到10倍以上。当模式串数目为1000个时,最佳加速比达到20倍。
4.3 基于GPU的其他多模式串算法改进
除了以上介绍的多模式匹配算法外,还有很多其他多模式串匹配算法也在不断发展。文献[24]利用后缀树方法进行并行匹配,应用在DNA序列匹配方面。文献[31]将位并行的算法运用在编辑距离(editdistance[44])方面。实验结果表明当文本长度小于37000时,匹配速度GPU比CPU匹配速度要慢,当文本长度大于37000时,匹配速度GPU要优于CPU。原因是GPU中有同步(synchronization)信号,会导致线程同步作用。因此当文本规模比较小的时候,GPU的扫描文本速度小于CPU。
文献[26]对ZZL[16]算法进行了并行改进,在GPU上实现,并对其时间复杂度进行分析,主要将ZZL算法的预处理阶段和匹配阶段构造两个核函数在GPU上实现。实验中文本数据选取蛋白质序列和DNA序列,在GPU上对改进后的ZZL和原ZZL的加速比进行了分析:在DNA序列字符串匹配实验中,加速比在112.0~113.0;在蛋白质系列序列字符串匹配实验中,加速比在56.7~57.5。
文献[45]中介绍了Sunday算法在GPU上的实现。文中对文本串的处理与3.2节一致。实验结果表明并行的Sunday算法加速比是传统Sunday算法的三倍左右。文献[25]在GPU上实现了基于位并行技术的多模式串匹配算法MBNDM (backwardnondeterministicdawgmatching)。通过在CPU上对需要处理的文本数据进行预处理,文本数据分割方式与3.2节一致,将串匹配的过程简化为更适合CUDA计算数据的位操作,随后在GPU上完成匹配部分。利用GPU可以使移植以后的位并行多模式串匹配算法与等同条件下的CPU程序相比获得约13倍的加速比。
5 基于gpu结构的算法改进
本章在AC算法的基础上,提出在GPU架构方面上的改进。下面只针对GPU架构方面进行介绍。Tumeo等人[30]首先提出两点对于GPU架构方面的瓶颈:a)分支操作要求在同一个warp中的线程等待所有其他线程都结束后才能进行下一步操作,这使得性能降低,因此分支操作需要考虑warp的粒度;b)共享存储器中有体冲突(bankconflict)。为了解决bankconflict,需要在一次访存操作中对于一个warp中的每个线程并行地读取相邻的内存单元的数据。此外,还有第三个问题是共享存储器受显存和存储控制器设计影响,只有按照对齐方式访问(coalescedread)时才能获得最大带宽。以上三个问题在此后的研究中具有巨大意义,有很多研究者也基于这三个方面进行了相应改进。
由于GPU的结构特性,在GPU上面的优化主要是基于分支操作、共享存储器和全局存储器三个方面展开的,其中分支操作中主要是基于循环展开进行的优化;共享存储器主要是针对bank冲突进行的优化,全局存储器主要针对对齐方式访问进行优化。
GPU分支操作方面
GPU的分支操作对于性能影响很大,主要在于一个warp中的线程需要等待所有其他线程都结束后才能进行下一步操作。分支操作主要针对if、switch等条件语句和for、while等循环语句。对于条件语句,主要针对数据预处理的方式,使得分支操作结束在同一个周期内,例如文献[33,36~38]就采用了数据预处
理的方式;对于循环语句,CUDA中有专门的关键字#pragmaunroll来进行优化,通常情况下会对循环展开和非循环展开进行对比,讨论其性能优劣,文献[19]就是利用循环展开的方式优化的。分支操作是CUDA编程中难以避免的一个问题,实际中需根据具体的问题处理不同的情况,以避免其影响。
5.2 GPU共享存储器方面
文献[35,46]对GPU共享存储器的bank冲突进行了改进。为了解决bank冲突问题,假设Sthread=224,tWord=Sthread/4=56(Sthread为单个线程处理的比特数据,tWord为单个线程处理的uint4数据,uint4是四维存储结构),则第t个线程处理的数据在t×tWord位置。由于不能在同一个bank中,即(t×tWord)mod16不能在相同的位置,作者用引理证明当tWord是奇数时,不会发生bank冲突。
文献[33,36~38]也意识到由于共享存储器是由多个memorybank组成,每个bank只能同时被一个线程访问,如果出现了同时访问,就会出现bank冲突。为了解决bank冲突问题,提出将数据访问时每次线程都是访问间隔16个以后的数据,这样避免了两个线程同时处理相同数据的现象,如图13和14所示。
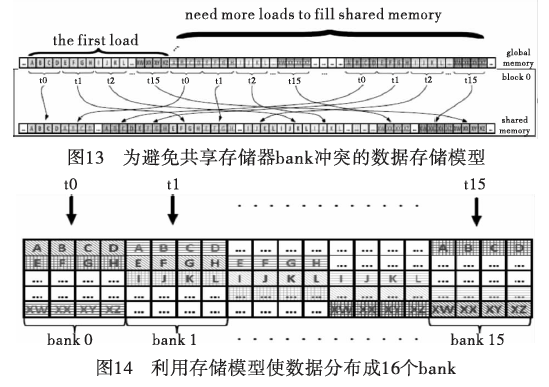
GPU 全局存储器方面
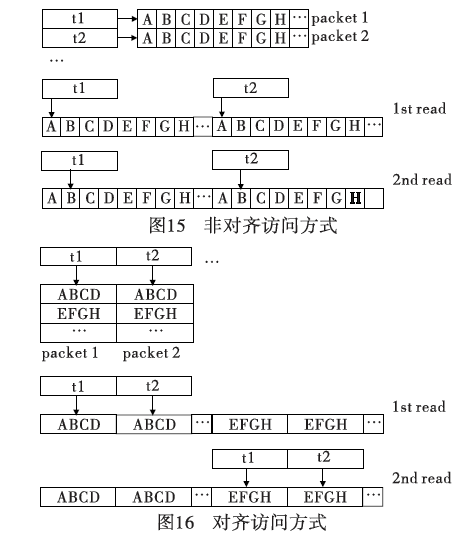
Tumeo等人[30]对于对齐方式访问的问题提出了解决方案,原始方法中将输入的文本流平分,每个单元称之为块(chunk),对于线程分配没有进行合并访问存储器,从图15中可以看到每个线程是间隔访问的数据,不利于对齐访问数据,造成带宽降低、访问延迟变大。文中提出的改进方案首先将输入的文本顺序重排,使得线程访问能够符合合并访问的要求,然后将文本块分割为每四个字节为矩阵中一个单元的列模型,如图16所示,所以每次访问时能够符合合并访问的要求,使得延迟最小。文献[27]将这种方法应用在TCP/IP包检测中,并且在GeForce9500M GS和TeslaC1060两种设备上做了GPU并行实验,并与IntelXeonE535进行了比较,得出加速比分别为2.85和6.67的结果。此后,作者在分布式和共享存储的并行结构中[32]又作了进一步研究,比较了在不同硬件环境下的吞吐量。
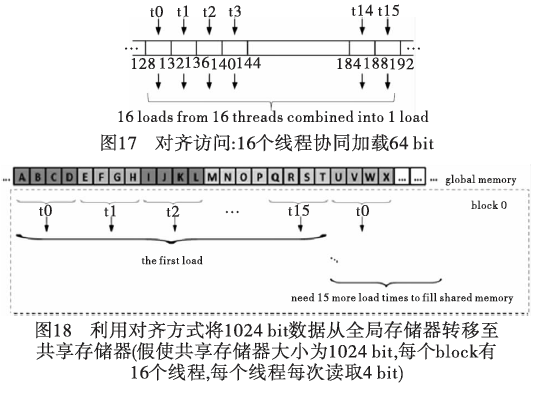
文献[33,36~38]等对GPU分层存储器数据访问的改进,由于GPU每次都是以半个线程束为单位同时进行的,为了减少从全局内存到共享内存的访问延迟,需要运用对齐方式访问的方法来一次性读取多个待匹配的文本数据到共享内存中,其结构可用图17和18表示。
优化后的方法将匹配数据从全局存储器转移到共享存储器中,发现采用对齐方式访问的方法比直接从全局存储器中取数据方法的加速比为7.3~19.3,比在单个CPU下的加速比为36.1~222.0.最优吞吐量可以达到125Gbps。
Zha等人[35,46]对GPU全局存储器的对齐访问也作了改进。TeslaGPU设备可以将半个线程束中的访问数据合并到一次事务中。合并技术经常发生在同一个线程束中多个线程访问连续的128Byte的情况下,当每个线程读取的字节多于128Byte,就会导致合并技术处于无效。由于每个线程先后读取的字节都不在相邻的单元中,所以每次事务只能访问有效字节数为1,带宽变为总的1/128。利用uint4的四维存储结构,一个线程每次读取4×4=16Byte,为了利用合并技术,每个线程访问的都是线程总数个之后的数据,相邻的线程访问的是相邻的数据,从而保证对齐访问的进行。
6 算法比较分析及评价指标
与传统的精确串匹配算法相比,基于GPU的串匹配算法在性能上有着明显的优势,更适用于入侵检测系统、深度包检测等方面。本章将讨论各个算法的优劣性并对基于GPU的精确串匹配技术的评价指标进行分析,便于研究人员参阅。
6.1 基于GPU的各算法优劣性比较
研究者对于算法的改进方式各有千秋,本文仅对前文中所列举的算法存在的优点和缺点进行了分析,详见表4。前文中3.2节提到过文本平均分割的方法,它能够使得各线程间防止出现文本漏检的情况,但是这种文本重叠的现象也使得算法吞吐量降低,线程的平均负载文本量减小。前文中介绍的KMP、WuManber、hash、gAC、BNDM、ZZL等算法改进都存在文本重叠的现象。类似BF、PFAC、PFACcompression等算法中对文本数据不存在依赖性,能从文本数据的任意位置进行读取,吞吐量相对来说比较高。从表4可以看出各算法的优缺点,这些优势与劣势对今后的研究能起到一定的启发作用。针对算法的优势,可以在GPU平台上有效加以利用;针对劣势,可以找出方法降低劣势带来的影响。总之,多种算法的优势和劣势可以指引今后研究中有针对性地进行扩展。

6.2评价指标方面
基于GPU的精确串匹配算法的评价指标根据文献的不同而具有差异性。根据文献归纳,主要有两个方面的评价指标:a)吞吐量,是指一段时间内测量出来的系统单位时间处理的任务数或事务数,在文献中所给出的单位基本上是Gbps或者Mbps。对于吞吐量来说需要考虑主机端到设备端的延迟时间、设备端到主机端的延迟时间以及在GPU执行时的吞吐量。对于不同的GPU设备来说,上述的参数会略有不同,在进行实验时需要考虑以上的因素所带来的影响。文献[28,39]中就考虑了延迟带来的影响。
b)加速比,主要将并行算法和串行算法的执行时间作为比值,从而得出并行算法的加速倍数。在进行性能分析时,常常利用线程数目、文本规模大小与吞吐量或者时间进行对照,分析实验性能。
此外,GPU中不同的存储器结构对于性能影响很大,表5列出了grid、block和thread各自可访问的存储器结构。其中,全局存储器、纹理存储器空间比较大,适合存储文本数据,全局存储器访问延迟较大,往往对文本数据存储位置进行优化处理;寄存器、本地存储器空间比较小,可存储线程间的私有变量;共享存储器可存储块block之间的私有变量,比寄存器和本地存储器要大一些,但空间有限,延迟比较小,在模式串规模不是很大的情况下存储在其中较为合适;常量存储器访问延迟也比较大,通常将内核函数的形参放入其中。
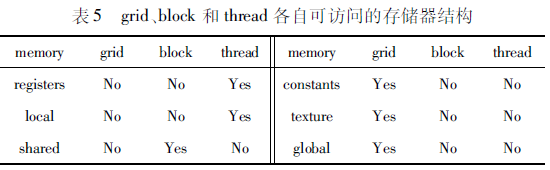
所以存储器结构不同,产生的访问延迟也不同,文献中文本数据和模式串数据如何分布到不同的存储器结构上也是影响性能指标的重要因素之一。
结束语
本文总结了近年来在GPU上基于CUDA模型实现的精确串匹配的算法。总体来说,由于算法之间的差异性,不同的算法改进方式也各不相同。本文介绍了经典的几种基于GPU的串匹配算法的改进方式,并且针对GPU的结构特性列举了具体的改进方法,最后对于算法的优劣和应用现状作了简要介绍,并对其中的评价指标进行了分析。下一步工作将从两个方面展开:
a)从本文中可以得出对于GPU的结构,需要考虑共享存储器的bank冲突、分支操作和全局存储器的对齐访问模式三个方面的改进。对于具体的串匹配算法改进形式多样,研究者可根据具体算法进行扩展。与此同时,也要注意GPU的存储器结构是否能负载模式串或文本数据的规模,根据存储器的分层结构进行具体优化。
结构进行具体优化。
b)针对基于GPU的精确串匹配算法的改进并不仅仅利用CUDA模型,对于OpenCL、OpenGL、OpenMP、MPI等利用CPU和GPU混合的方法也层出不穷,研究者可针对上述GPU混合的模式实现多样性并行匹配。面对新型GPU设备的逐步更新换代,如何应对新型GPU结构、如何应用GPU的新技术(如zerocopy、HyperQ技术等)这些问题都面临着巨大的挑战。本文所列举的性能仅仅是针对单台GPU设备或者多台GPU设备分别实践所得出的,如何面对多台GPU相互协作这一工作模式也是研究者亟需解决的一大问题.
结束语
本文对各种基于GPU的串匹配算法进行了回顾,包括单模式串、多模式串等,介绍了基本原理以及在GPU上的改进。最后比较了各算法的优缺点,并对算法进行了总结与展望。
参考文献:
[1] Snort公司.Snort[EB/OL].[20151101].https://www.snororg/.
[2] KharbutliM,AldwairiM,MughrabiA.FunctionanddataparallelizationofWuManberpatternmatchingforintrusiondetectionsystems[J].NetworkProtocolsandAlgorithms,2012,4(3):4661.
[3] 李伟男,鄂跃鹏,葛敬国,等.多模式匹配算法及硬件实现[J].软件学报,2006,17(12):24032415.
[4] KirkDB,HWuW M.大规模并行处理器编程实战[M].陈曙辉,
熊淑华,译.北京:清华大学出版社,2010.
[5] NVIDIA公司.NVIDIA[EB/OL].[20151101].http://www.nvidia.cn/page/home.html.
[6] KouzinopoulosCS,MargaritisKG.StringmatchingonamulticoreGPUusingCUDA[C]//VassiliosC,NikolaosA,ChristosD,etal.Procofthe13thPanhellenicConferenceonInformatics.WashingtonDC:IEEEComputerSociety,2009:1418.
[7] NagaveniV,RajuGT.VariousstringmatchingalgorithmsforDNA sequencestodetectbreastcancerusingCUDA[J].InternationalJournalofEngineering&Technology,2014,14(3):42.
[8] NavarroG,RaffinceM.柔性字符串匹配[M].中科院计算所网络信息安全研究组,译.北京:电子工业出版社,2002.
[9] BoyerRS,MooreJS.Afaststringsearchingalgorithm[J].CommunicationsoftheACM,1977,20(10):762772.
[10]KnuthDE,JrMorrisJH,PrattVR.Fastpatternmatchinginstrings[J].SIAM JournalonComputing,1977,6(2):323350.
[11]KarpRM,RabinM O.Efficientrandomizedpatternmatchingalgorithms[J].IBM JournalofResearchandDevelopment,1987,31
(2):249260.
[12]AhoAV,CorasickMJ.Efficientstringmatching:anaidtobibliographicsearch[J].CommunicationsoftheACM,1975,18(6):333340.
[13]WuSun,ManberU.Afastalgorithmformultipatternsearching,TR9417[R].Tucson:DepartmentofComputerScience,UniversityofArizona,1994.
[14]McCreightEM.Aspaceeconomicalsuffixtreeconstructionalgorithm
[J].JournaloftheACM,1976,23(2):262272.
[15]NavarroG,RaffinotM.Fastandflexiblestringmatchingbycombi
ningbitparallelismandsuffixautomata[J].JournalofExperimentalAlgorithmics,2000,5(4):2000..
[16]纪福全,朱战立.一种可做特殊用途的字符串匹配算法[J].计算机与信息技术,2006,2006(8):028.
[17]张庆丹,戴正华,冯圣中,等.基于GPU的串匹配算法研究[J].计算机应用,2006,26(7):17351737.
[18]ShirudeR,NikamVB,MeshramBB.PerformanceefficientDNAse
quencedetectiononGPU usingparallelpatternmatchingapproach
[J].InternationalJournalofComputerScienceandInformationTechnologies,2014,5(4):53805385.
[19]BellekensX,AndonovicI,AtkinsonR C,etal.Investigationof GPUbasedpatternmatching[C]//Procofthe14thAnnualPost GraduateSymposiumonConvergenceofTelecommunications,NetworkingandBroadcasting.2013.
[20]HungCL,WangHH,ChangCY,etal.EfficientpacketpatternmatchingforgigabitnetworkintrusiondetectionusingGPUs[C]//Procofthe14thInternationalConferenceonHighPerformanceComputingandCommunication&the9thInternationalConferenceonEmbeddedSoftwareandSystems.2012:16121617.
[21]HungCL,LinCY,WangHH.AnefficientparallelnetworkpacketpatternmatchingapproachusingGPUs[J].JournalofSystemsArchitecture,2014,60(5):431439.
[22]XuDongliang,ZhangHongli,FanYujian.TheGPUbasedhighperformancepatternmatchingalgorithmforintrusiondetection[J].JournalofComputationalInformationSystems9,2013,2013(10):37913800.
[23]马计,王国平,杨明.基于CUDA的WuManber多模式匹配算法[J].计算机系统应用,2012,21(3):5154.
[24]SchatzM C,TrapnellC.FastexactstringmatchingontheGPU,Technicalreport[EB/OL].(20070508).http://m.gpucomputing.net/sites/default/files/papers/3152/Cmatch.pdf.
[25]赵光南,吴承荣.基于GPU的位并行多模式串匹配研究[J].计算机工程,2011,37(14):265267.
[26]谷岳,谷建华.基于GPU加速的并行字符串匹配算法[J].微电子学与计算机,2013,30(9):3033.
[27]TumeoA,VillaO,SciutoD.EfficientpatternmatchingonGPUsforintrusiondetectionsystems[C]//Procofthe7thACM InternationalConferenceonComputingFrontiers.NewYork:ACMPress,2010:8788.
[28]LinCH,TsaiSY,LiuCH,etal.AcceleratingstringmatchingusingmultithreadedalgorithmonGPU[C]//ProcofGlobalTelecommunicationsConference.2010:15.
[29]PengJianghu,ChenHu,ShiShaohuai.TheGPUbasedstringmatchingsysteminadvancedACalgorithm[C]//Procofthe10thInternationalConferenceonComputerandInformationTechnology.2010:11581163.
[30]TumeoA,SecchiS,VillaO.Experienceswithstringmatchingonthefermiarchitecture[C]//MladenB,WilliamF,UweB,etal.Procofthe24thInternationalConferenceonArchitectureofComputingSystems.Berlin:Springer,2011:2637.
[31]YangC,ZhangK.Parallelapproachestoeditdistanceandapproximatestringmatching[EB/OL].(20140510)[20151101].ht
tp://caryyang.me/editdistance/finalparalleledit.pdf.
[32]TumeoA,VillaO,ChavarríaMirandaD G.AhoCorasickstringmatchingonsharedanddistributedmemoryparallelarchitectures[J].IEEETransonParallelandDistributedSystems,2012,23(3):436443.
[33]TranNP,LeeM,HongS,etal.MemoryefficientparallelizationforAhoCorasickalgorithmonaGPU[C]//Procofthe14thInternationalConferenceonHighPerformanceComputingandCommunication&the9thInternationalConferenceonEmbeddedSoftwareandSystems.
2012:432438.
[34]陈虎,彭江锋,施少怀.gAC:基于GPU的高性能AC算法[J].计算机工程与应用,2012,48(12):4348.
[35]ZhaX,SahniS.GPUtoGPUandhosttohostmultipatternstringmatchingonaGPU[J].IEEETransonComputers,2013,62(6):11561169.
[36]TranNP,LeeM,HongS,etal.PerformanceoptimizationofAhoCorasickalgorithmonaGPU[C]//Procofthe12thIEEEInternationalConferenceonTrust,SecurityandPrivacyinComputingandCommunications.2013:11431152.
[37]TranNP,LeeM,HongS,etal.HighthroughputparallelimplementationofAhoCorasickalgorithmonaGPU[C]//Procofthe27th
InternationalConferenceonParallelandDistributedProcessing&PhD
Forum.2013:18071816.
[38]TranNP,LeeM.Highperformancestringmatchingforsecurityapplications[C]//Procof2013InternationalConferenceonICTforSmartSociety.2013:15.
[39]LinCH,LiuCH,ChienLS,etal.AcceleratingpatternmatchingusinganovelparallelalgorithmonGPUs[J].IEEETransonComputers,2013,62(10):19061916 TransonImageProcessing,2001,10(2):266277.[43]郝家胜.基于几何流的医学图像分割方法及其应用研究[D].哈
尔滨:哈尔滨工业大学,2008.
[44]贾同,魏颖,吴成东.基于几何形变模型的三维肺血管图像分割方
法[J].仪器仪表学报,2010,31:22962301.
[45]AgamG,ArmatoSGI,WuC.Vesseltreereconstructioninthoracic CTscanswithapplicationtonoduledetection[J].IEEETransonMedicalImaging,2005,24(4):486499.
[46]FrangiAF,NiessenW J,VinckenKL,etal.Multiscalevesselenhancementfiltering[C]//MedicalImageComputingandComputerAssistedInterventation.Berlin:Springer,1998:130137.
[47]尚岩峰,汪辉,汪宁,等.管状特性和主动轮廓的3维血管自动提取[J].中国图象图形学报,2013,18(3):290298.
[48]KorfiatisPD,KalogeropoulouC,KarahaliouAN,etal.VesseltreesegmentationinpresenceofinterstitiallungdiseaseinMDCT[J].IEEETransonInformationTechnologyinBiomedicine,2011,15
(2):214220.
[49]KuhnigkJM,HahnH,HindennachM,etal.Lunglobesegmentationbyanatomyguided3Dwatershedtransform[C]//ProcofSPIE,MedicalImaging:InternationalSocietyforOpticsand Photonics.2003:14821490.v
[50]UkilS,ReinhardtJM.AnatomyguidedlunglobesegmentationinX
rayCTimages[J].IEEETransonMedicalImaging,2009,28(2):202214.
[51]VanRikxoortEM,DeHoopB,VandeVorstS,etal.AutomaticsegmentationofpulmonarysegmentsfromvolumetricchestCTscans[J].IEEETransonMedicalImaging,2009,28(4):621630.
[52]ZhangLi,HoffmanEA,ReinhardtJM.AtlasdrivenlunglobesegmentationinvolumetricXrayCTimages[J].IEEETransonMedicalImaging,2006,25(1):116.
[53]VanRikxoortEM,ProkopM,DeHoopB,etal.Automaticsegmentationofpulmonarylobesrobustagainstincompletefissures[J].IEEETransonMedicalImaging,2010,29(6):12861296.
[54]DiciottiS,LombardoS,FalchiniM,etal.AutomatedsegmentationrefinementofsmalllungnodulesinCTscansbylocalshapeanalysis[J].IEEE TransonBiomedicalEngineering,2011,58(12):34183428.
[55]DiciottiS,PicozziG,FalchiniM,etal.3DsegmentationalgorithmofsmalllungnodulesinspiralCTimages[J].IEEETransonInformationTechnologyinBiomedicine,2008,12(1):719.
[56]KostisW J,ReevesAP,YankelevitzDF,etal.ThreedimensionalsegmentationandgrowthrateestimationofsmallpulmonarynodulesinhelicalCTimages[J].IEEETransonMedicalImaging,2003,22(10):125974.
[57]KuhnigkJM,DickenV,BornemannL,etal.MorphologicalsegmentationandpartialvolumeanalysisforvolumetryofsolidpulmonarylesionsinthoracicCTscans[J].IEEETransonMedicalImaging,2006,25(4):417434
[58]OkadaK,ComaniciuD,KrishnanA.RobustanisotropicGaussianfittingforvolumetriccharacterizationofpulmonarynodulesinmultisliceCT[J].IEEETransonMedicalImaging,2005,24(3):409423.
[59]BoykovY,JollyM.Interactiveorgansegmentationusinggraphcuts[C]//Procofthe3rdInternationalConferenceonMedicalImageComputingandComputerAssistedIntervention.2000:276286.
[60]BoykovY,KolmogorovV.Anexperimentalcomparisonofmincut/maxflowalgorithmsforenergyminimizationinvision[J].IEEE
TransonPatternAnalysis&MachineIntelligence,2004,26(9):11241137.
[61]FordL,FulkersonD.Flowsinnetworks[M].NewJersey:PrincetonUniversityPress,1962.
[62]GoldbergA V,TarjanR E.A newapproachtothemaximumflowproblem[J].JournalofthAssociationforComputingMachinery,1988,35(4):921940.
[63]BoykovY,VekslerO,ZabihR.Fastapproximateenergyminimizationviagraph cuts[J].IEEE Trans on Pattern Analysis &MechineIntelligence,2001,23(11):12221239.
[64]YeX,SiddiqueM,DouiriA,etal.Graphcutbasedautomaticseg
mentationoflungnodulesusingshape,intensityandspatialfeatures
[C]//Procofthe2ndInternationalWorkshoponPulmonaryImageA
nalysis.2009:103113.
[65]YeX,BeddoeG,SlabaughG.Automaticgraphcutsegmentationof
lesionsinCTusingmeanshiftsuperpixels[J].InternationalJournal
ofBiomedicalImaging,2010,2010:112.
[66]HintonGE.Reducingthedimensionalityofdatawithneuralnetworks[J].Science,2006,313(5786):504507.
[67]HintonGE,OsinderoS,TehYW.Afastlearningalgorithm fordeepbeliefnets[J].NeuralComputation,2006,18(7):15271554.
[68]EgmontPetersenM,RidderDD,HandelsH.Imageprocessingwith
neuralnetworks:areview[J].PatternRecognition,2002,35(1):
22792301.
[69]MisraJ,SahaI.Artificialneuralnetworksinhardware:asurveyoftwodecadesofprogress[J].Neurocomputing,2010,74(13):239255.
[70]LiQing,CaiWeidong,WangXiaogang,etal.Medicalimageclassificationwithconvolutionalneuralnetwork[C]//Procofthe13thInternationalConferenceonControlAutomationRoboticsandVision.2015:844848.
[71]李梭.肺部CT影像慢阻肺病灶三维定量化分析研究[D].上海:
中国科学院研究生院(上海技术物理研究所),2014.
[72]LoP,VanGinnekenB,ReinhardtJM,etal.ExtractionofairwaysfromCT(EXACT’09)[J].IEEE TransonMedicalImaging,2012,31(11):20932107.
[73]LOLA11[EB/OL].http://www.lola11.com/.
[74]VESSEL12[EB/OL].http://vessel12.grandchallenge.org/.


